Multiverse 2.357
paused to apply patches
Authentication in computer systems means validating that you are who you say you are. There are many ways to authenticate users these days, and they have important implications for privacy. Username and password combinations are problematic, yet we don’t really have great alternatives at this point.
Fingerprints and facial recognition systems are the most common forms of biometric authentication, and are already used in many smartphones. They are certainly convenient, but come with security and privacy problems of their own. If collections of this biometric identification data are collected and stored it may well be altered or stolen.
Read MoreIn our last search engines post called Internet of Things Searching we discussed services that scan the Internet every day giving users easy ways to drill down into those results. Users can get detailed searches for routers, webcams, RDP service, Nginx web servers, SCADA controllers or whatever, as well as access robust APIs so these search data can be integrated into other systems. Today we talk about basically the opposite – user curated, decentralized general search.
YaCy is a decentralized, peer-to-peer search engine which can be run locally. Being a decentralized search engine means that it runs on volunteer nodes around the world and the creators have no idea how many people are using it or who they are. That means no search engine company knows about your search data, but also means that the quality of results depends on having a critical mass of people using it.
Read MoreYesterday’s Hacker Public Radio podcast was an introduction to Bitcoin that I recorded recently. The audio is terrible, but hopefully the content is less than terrible. I’m not sure if there’s much of an audience on HPR for Bitcoin and blockchain related content – we’ll see.
Here is what I tried to cover:
- What is Bitcoin?
- Blockchains and blocks
- What are transactions?
- What are miners and what do they do?
- Proof of Work in Bitcoin – SHA256 hashing
- Bitcoin consensus mechanism
- How do wallets work?
- Brief discussion about types of wallets and wallet security
According to the introduction page on the scapy documentation website:
Scapy is a Python program that enables the user to send, sniff and dissect and forge network packets. This capability allows construction of tools that can probe, scan or attack networks.
What that doesn’t tell you is that scapy can be used interactively or imported into your python programs. It can do a lot more than they claim above too like craft custom packets for all major network protocols including weird ones like TFTP, read and write packet capture (pcap) files, establish socket connections, deal with encryption, send ethernet or wireless frames (even invalid ones), and much more.
Read MoreThe proliferation of cameras in the modern world is no fad, it continues unabated. Here is an image (shown below) from a 2016 patent application from Sony Corporation for a digital camera built into a contact lens. Notice that it has wireless communications capability and a storage unit to offload images and upgrade the software and firmware.

We talked about Google Search in the previous post on the topic of search engines, but now we’re going to shift gears and take a look at some search engines specialized for searching the Internet of Things (IoT). The 800 pound gorilla in the space is Shodan, that lets users search the Internet for devices by category, protocol and more. Shodan is integrated with network discovery and exploit tools, as well as web browsers.
Common searches might be searching across the Internet for webcams, traffic signals, industrial control systems, specific services running, or devices with default passwords. Results tend to have addresses, hostnames, open ports and other details.
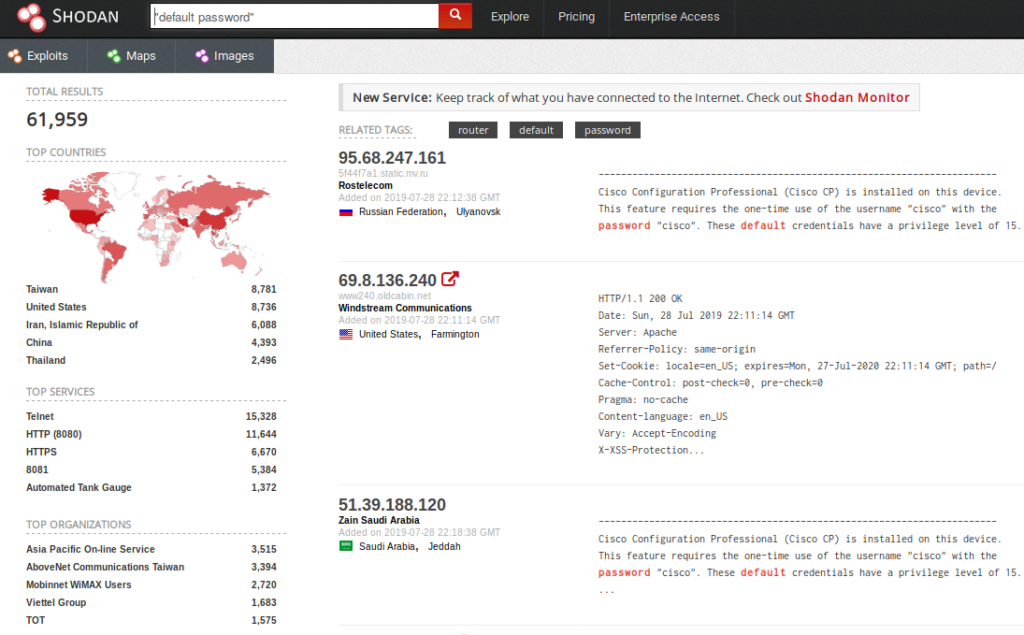
Shown above is the first three results for a search for “default password” that returned 16,959 matches. The result set can be refined by choosing country, services, etc. from the menu in the left column. As you can see, the relevant information is displayed about each device and the software running on it, along with unusual things noted.
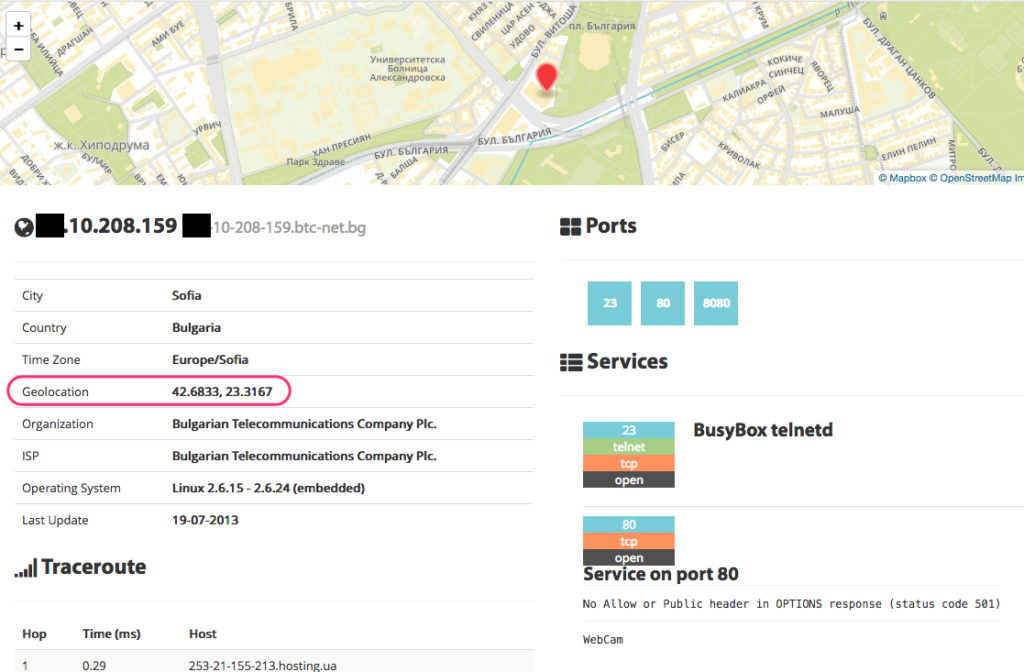
If we click on one of the results we navigate to a detail page (shown above) for that particular device. It shows the location of that device on a map (below) along with the GPS coordinates. It also shows us the open ports, along with relevant information about the services listening on those ports.
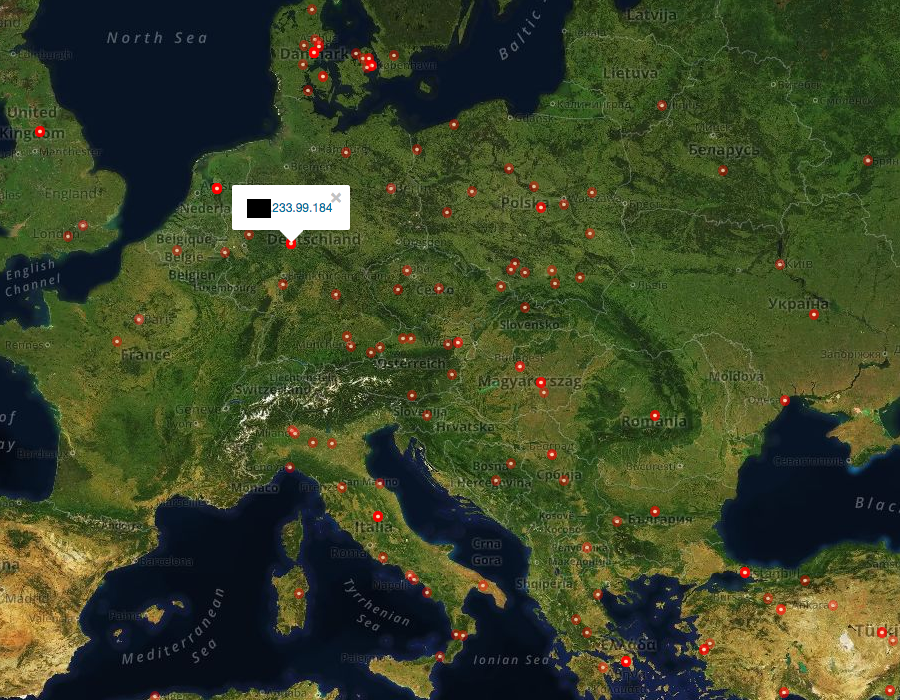
Shodan can show us entire populations of devices – anything from a model of smart TV to routers with a certain firmware version. Alerts can be setup to create a monitoring system. You might want to check Shodan after installing a new networked device.
Shodan can be installed locally, and can be used programmatically via the API. Heavy users can use the API to script common searches for specific devices or ports to great effect. You probably don’t want your insecure web cams, baby monitors or smart TVs showing up in some of these searches, so always check to ensure that you’ve taken reasonable precautions like changing default passwords.
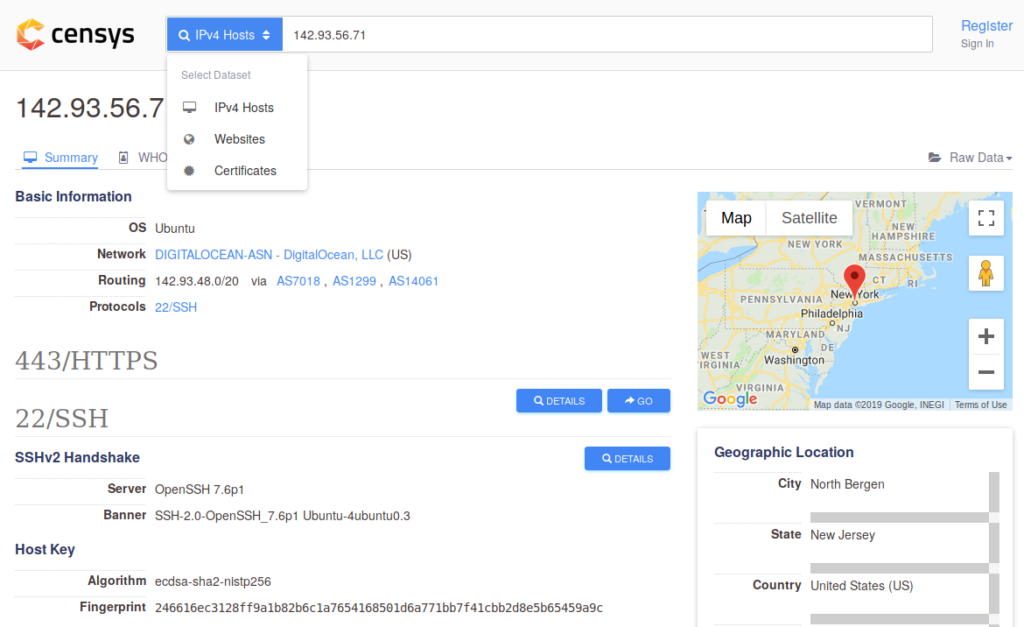
Perhaps the leading competitor is Censys, that has a similar offering. They scan the Internet and organize their findings in a way that is easy to navigate and drill down for details. They also have a full Restful API and are widely used by enterprise customers.
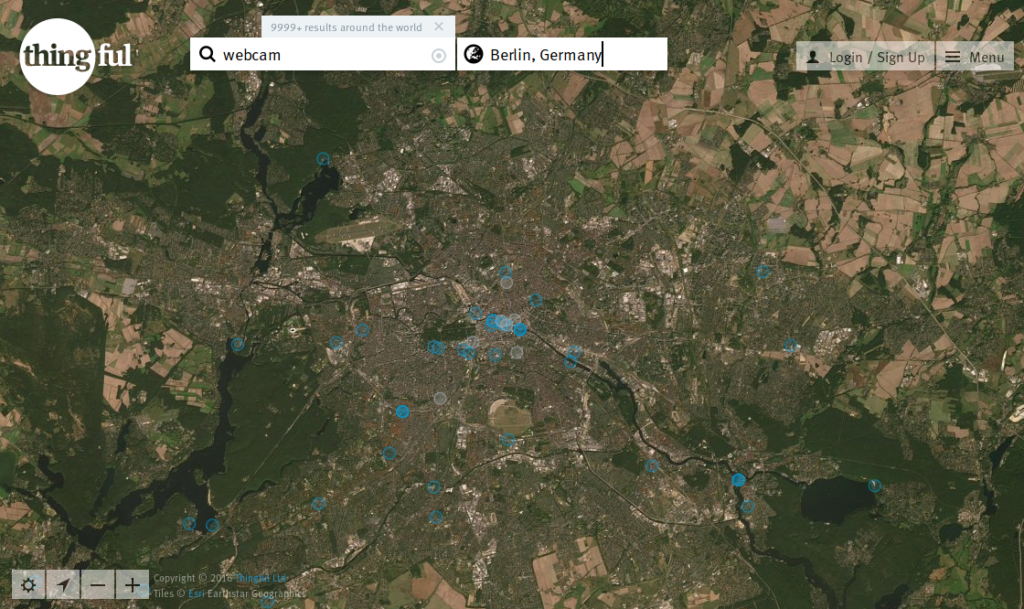
Another competitor is Thingful, whose specialties include working on locating connected vehicles. Of course they’re connected but they are often moving around, so this solution sounds ideal for operators of fleets of taxis or long-haul trucks.

Then there is Reposify, a company that aims to serve the corporate market for geographically diverse firms that want to monitor their public-facing attack surface. They too offer a robust API and scan the Internet constantly.
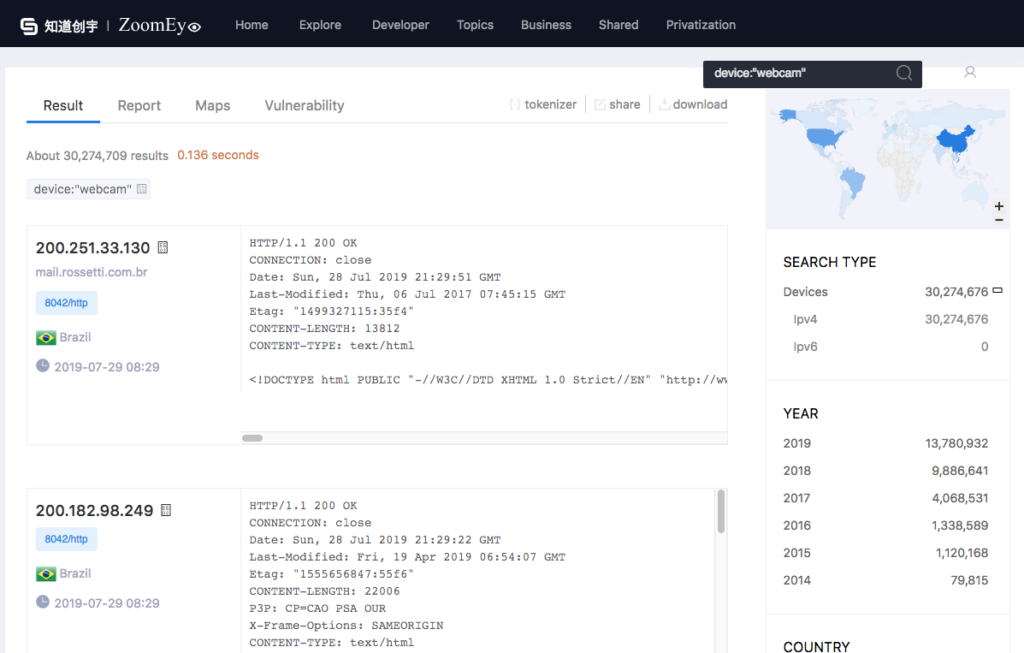
Another IoT search service is called ZoomEye that seems to offer very much the same feature set that Shodan does including detailed search queries and a rich API.
As you can see there are quite a few services that scan the Internet looking for connected devices, certain services and ports, specific devices or manufacturers and much more. I’m sure there are others that we did not include as this is a popular and growing space for search. Next, we’re going to take a look at decentralized search engines – stay tuned!
Some image file formats like the ubiquitous JPEG standard, have file headers and metadata that can be scrutinized for signs of tampering in suspicious circumstances. There are increasing numbers of cases where malicious people take photographs of people and tamper with them, in order to create fake and compromising images for the purpose of blackmail or revenge. These file headers and metadata can sometimes reveal that the photos were tampered with.
The flip side of that is protecting your privacy by being aware of these identifiers. As a privacy conscious person, you should consider taking reasonable steps to avoid giving away any extra information when doing normal things, like posting a head shot on a dating website. It’s not just forensics specialists that are interested in this digital evidence, stalkers find it just as useful.
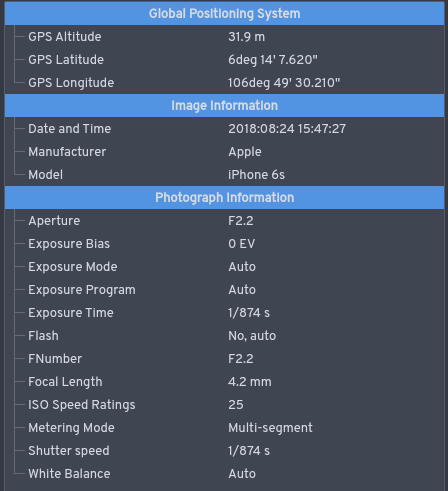
When looking at JPEG images, image sizes represent device capabilities and can distinguish between cameras that use different image resolutions. Metadata provides a wealth of device-specific and situational information. Some devices store thumbnail images along with the actual image data, but not all thumbnail images are created equally. These thumbnails have all the same sorts of identifiers as the original images. You can obviously control the size of an image you’re about to post onlineby cropping or resizing. Now let’s take a look at the metadata and what it reveals.
Devices that take real world inputs and digitize them typically embed metadata into the digital files produced. There is a standard for this called Exchangeable Image File (EXIF) format that is widely used in cameras, scanners and audio recorders, and by the camera in your smartphone. If you take a photograph with your camera, the visualinformation is stored in a file along with extra information including the type of camera used, the time and date, the geolocation of the image and quite a bit more.
This “metadata”, or data about the data file, is not encrypted and can be read by anyone. The good news, or bad news, depending on your perspective is that it can easily be removed, changed or faked. There are some “required” fields for whatever reason, but they are not the fields that give away the most sensitive information.
Note also that there can be several types of metadata in your photographs including XMP, IPTC data, and JPEG comments. It is also possible to embed data in the file itself using steganography – a topic we’ll cover in detail in future posts. Today we’re simply talking about data about the photo.
There are a variety of tools to read and modify EXIF data but our favorite is definitely Phil Harvey’s exiftool program. This is a command line utility that lists, modifies and removes fields. We’ll explore using this great tool from the command line and in python scripts, along with some similar tools in an upcoming post.
From a privacy perspective, the most potentially damaging data fields reveal your location, device details and the date and time the photo was taken. If you upload photos using your smartphone, you might want to install an app to strip EXIF data before posting. This is less than ideal OPSEC, since you are not cropping and saving in lossy format to reduce the quality of indicators like scratches or dust on the lens that allow companies like Facebook to identify you and your device.
Facebook, Twitter, Instagram and many other large social media sites automatically remove EXIF data from photographs you upload, so your home location is not going to be accidentally revealed. But others don’t, and it’s not removed when you send media by email, share images using instant messenger apps, post your pics on a cloud storage site like Google Drive, share on an image site like Imgur or send files by SMS.
Removing EXIF data is easy on every major platform, including Android, iOS, Windows, OSX and Linux. Even if you put photos online after the fact, patterns of movement emerge from multiple images that might indicate where you live and work, where else you go and when, and predictable routines like weekly visits to specific places. Consider what data you’re permanently sharing with the entire Internet before sharing.
Your photos from the big televised sporting event might not need to have location stripped out, as it might be obvious where and when the photos were taken. For example if player names are visible on uniforms, it might be easy to tell in what game they were taken. But you might not want to disclose the type of device you are using, so removing EXIF data makes sense even in these cases.
If the photo is to be shared publicly, or stored in the cloud, removing the EXIF data is always the recommended behavior. There are just too many clues in this metadata. For example, if you cropped the image using image processing software like Photoshop, someone looking at it may be able to discern what version of software on which operating system you used. Unique photo identifiers are assigned commonly by smartphones, and can be used for determining in which order photographs were taken.
As far as altering the EXIF data goes, it is important to remove or change the EXIF data before the file is put in any public place, not after. This is because the versions can be compared using common forensic techniques and the change will be detected.
Remember the same EXIF data can be present in audio and video recordings too, not just images. This applies not only to data captured from your smartphone and camera, but also medical images and more. Every digital recording of real world data data should be checked before sharing online.
However if it’s important to you to leave evidence that supports a claim of authenticity, then you might want to leave the EXIF data as is. Consider for example, that instead of a sporting event your photos came from the scene of an auto accident or newsworthy event. If the purpose of a photograph is documenting something to be used as evidence, leave the EXIF data untouched, to avoid giving the appearance of tampering.
So when you really, really want to post that amazing photo you just snapped on your smartphone – consider removing the metadata first.
This is the third part in a series on cameras and photographs that started with Cameras, Photos and People and then proceeded to considertechniques for Camera Fingerprinting. Next, we’ll take a look at what we can expect in upcoming camera technologies.

Photographs have clues that are specific to a camera. Tiny clues, but given a group of photos form the same camera it quickly becomes obvious that they did come from the same source. Once that happens, every photo you ever take is identified as coming from your camera, on your phone, and associated to you.
Most readers at this point would probably think, “Why should I care?” The answer is that this does not just affect investigative journalists. It will affect us all because as AI systems get more capable, they can infer an amazing amount about your life from a collection of seemingly unrelated facts. Bots scour the Internet now, gathering and organizing collections of photos. The current AI technology is not advanced enough to definitively associate all photos to the people who took them, for various reasons. These reasons are just temporary technical roadblocks – they will be overcome in time.
One very sophisticated method of demonstrating that camera images came from the same device has to do with patterns of noise generated by heat in that device. Noise signatures in photographs come from ambient thermal heat, and thermal heat generated in the camera – inside the charged coupled device (CCD) itself.
Astrophysicists have long been interested in this, but the easiest solution for them is supercooling the camera, which is not an option for a mobile phone user. Camera manufacturers have built products that heat the CCD just before taking a picture, but to date this is not available in mobile phones.
Mobile phone cameras product images that display patterns of random noise in the least significant bits (LSB), which basically means the colors are altered only a tiny amount. This alteration is small, so that a human eye can’t detect it but computers can see these patterns and easily determine that it came from a certain camera.
Unfortunately, for those without a forensics lab, the easiest way to make this difficult to detect is to degrade the image. A quick and easy way to make this signature less obvious would be to save in a lossy format like JPEG, then crop or resize and save again. The obvious problem is that this is noticeably making your photos look worse.
Moreover, you would need to vary this process of saving, altering and
saving each time to avoid simply changing the pattern to be detected.
As if that weren’t daunting enough already, you probably need to save
with fairly high compression so that it really is a lossy process. That
is not something you can completely mitigate without extreme effort, but
in the
process of avoiding simpler techniques you can make this more difficult.
So with that out of the way, let’s look at simpler ways of determining that photos come from the same camera; ways that you have more control over. Dust and scratches are an easy ways to determine that a group of images all came from the same camera. Tiny specs of dust unnoticeable to the eye can prevent certain pixels from changing in any of your photographs. Facebook has patents for identifying a camera based on faulty pixel positions caused by dust, scratches and similar conditions.
Clean the lens of the phone’s cameras with a cleaning cloth made for cameras or eyeglasses to increase your chances of avoiding this issue. Also try to take pictures of a wider physical range than you actually need, and crop the image in the processing phase. Other techniques that can help are resizing the image and adding adjustment layers – both can alter the pixels to avoid those dust dead spots.
This post is a followup to the previous post Cameras, People and Photos. I have a lot more to say about this topic, so stay tuned for the next installment where I want to take a closer look at JPEG files, EXIF data and digital photographs.

Google has long dominated the field of search engines in terms of market share, sporting a 77% market share in a recent survey, but many have expressed concerns about the search giant. The immensity and complexity of this search behemoth is nothing short of amazing.
According to internetlivestats.com, “Google now processes over 40,000 search queries every second on average, which translates to over 3.5 billion searches per day.” A search query using Google uses 1000 servers, happens in 0.2 seconds and travels over 1500 miles.
The principal concern for privacy advocates is Google’s business model, which is based on building user profiles and monetizing their behavior data. The incredible power Google has to build a composite profile is based on the wide range of Google services people use.
Google gathers data from Google search engine, Google calendars, Gmail, Picassa photo sharing, Youtube, Blogger, Google docs, credit card info via Google checkouts, news feeds via Reader, sites visited via Google analytics, file storage via Google Drive, smartphone usage data via Android operating system, app usage via Google Play, location information via Google maps and Waze, ad viewing and click data via Google Adsense and DoubleClick, browser-specific information via Google Chrome, and more.
There are other sources as well, but these are the most important ones in our view. Search data that is logged reveals over time an incredibly detailed portrait of a user. The personal and professional details of the user are revealed along with health and medical information, political preferences, interests and aspirations, hobbies, sexual orientation, financial situation, travel plans, religious beliefs, shopping interests and so much more.
Every letter typed, every phrase searched for, every result clicked on is significant and is recorded, because this data has an impact on Google’s profitability. However, when people know their activities are being recorded, they act differently. This is strikingly evident in activities like searching. For example, monitoring people’s behavior suppresses searches for health information.
Drawing conclusions from search data can be highly misleading too, as the search terms do not clearly reflect user intent. A search query like “presidential assassination” does not necessarily indicate the user is considering committing this crime, but could be a student writing a history paper. A searcher who queries “growing marijuana” might be someone who wants to learn how to grow it, but could also be a parent concerned over growing marijuana use in schools.
The combination of misleading search queries, ease of government access, the lack of transparency Google and others provide, and the inability of users to know how this data is used creates a problematic privacy issue.
Less obvious but problematic nevertheless is the filter bubble effect. Search results are biased based on your search history, and the results you see are those which are most likely to get clicked. So if you’re researching, you get tailored content instead of useful results. On a global scale it creates polarization, inhibits journalists from effectively researching topics, and reinforces the notion that many are living in online echo chambers – all for the sake of advertising profits.
To be fair, search engines want to analyze search data in order to improve search results ; those results that get clicked on most are the ones people are essentially voting on, which is a proxy for being the most relevant or useful. Search logs may also protect the search service from attack, and provide data that helps them to avoid those who would game the system in order to attract more visitors. But Google keeps far more data than what is needed to maintain quality results, so privacy minded individuals should really consider using a different search service that does not operate in such an invasive manner, does not have the ability to correlate data from so many sources, and does not base its business on the resale value of personal data.
In ethical, and increasingly legal terms, one of the principal issues is the secondary uses of the data – specifically search terms and the associated user profile data. By searching, users are explicitly giving consent to use these terms or phrases to generate a search result set. However, when it is combined with information from other sources it becomes a powerful indicator and the user may not be aware of what happens to their search history that is logged and aggregated over months or years.
For these reasons many privacy conscious people have increasingly been choosing alternative search engines in recent years. We’ve also seen a surge in specialized search engines that are doing a better job serving niches. This started with the major search engines like Google Search and Bing offering image and video searches, and has exploded in recent years to supplement the general purpose search services.
In the 1990s ther were a variety of search engines and search aggregators that were competitive but for years now this space has been dominated by Google search. They still dominate search, yet specialized search services are thriving too. In upcoming posts, I plan to explore decentralized search engines, IoT search engines, OSINT focused search engines, search services specializing in finding technical, medical and legal documents and more. Stay tuned for a closer look at searching.
Camera technology is not what it was a generation ago. Photogaphs and videos captured using smartphones have revolutionized how we see the world, how we share information and how we document our lives. But few understand the technologies involved and how they are analyzed. In these next few posts I want to share what I know about this topic, which is limited and will be getting outdated by the time I finish typing this introduction.
Most of us use mobile phones because they are incredibly convenient. The actual phone function is only one of many that we use though; another important feature are the cameras. With builtin 12 megapixel cameras being no big deal, we take photos of food, scenery, friends, and of course selfies. What we don’t realize is that it’s important for “big marketing” to identify cameras, and the photos they take, and match them to people.
Surveillance cameras are going through an unprecedented population growth, and feed data into AI systems that identify us by our faces and our gait. They combine this with realtime location data from our phones and suddenly every detail of your activity since you stepped out of your house is known and recorded.
We post them to social media sites as if the world needed to know where we ate lunch. We pull them into apps to manipulate them, put cute sunglasses on our selfies and use apps to share them with the entire planet for all of recorded history. Welcome to a tiny preview of what we can expect in the future.
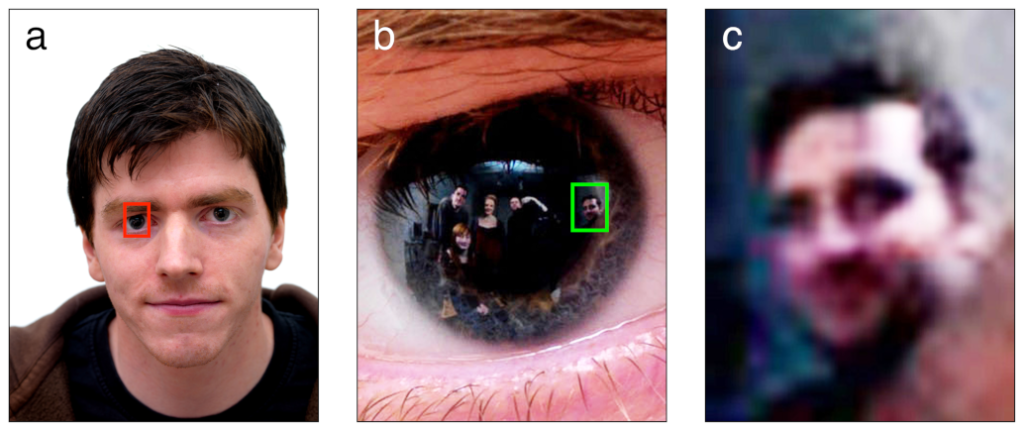
People dramatically underestimate how much information is available to anyone analyzing their posted photographs. Aside from information about your camera which is linked to you, a lot of extraneous data can be extracted from photographs. For example, shown above is a system that identifies people not in line of sight of a camera by their reflection in someone’s cornea! In the image above, we see five individuals identified from the reflection in the eye of a person in view of a camera.
Identifying images and determining that they came from a specific camera, or were manipulated with a computer program associated to a specific individual is important. Photographs are used as evidence in courtrooms, and forensics is used to support the validity claims. However, if you are determined to post a selfie on a dating site, you should take precautions to not include too much evidence that identifies you.
Next we’re going to take a closer look at camera fingerprinting. You might be surprised at the sophistication of the techniques used.
Here we go again, yet another blog by yours truly. I had a blog for years here, and have dabbled in some other places since then.
I enjoy writing, and here I intend to share whatever I’m interested in. That should amount to a heavy dose of cybersecurity, along with blockchain, digital privacy and computer technology. If you follow really close you might even notice a post here and there about space exploration, quantum computing or sushi.

The first page archived by the Wayback MachineTM on this domain was in May 2001, and was a simple contact page. It ran a CGI script that I thought was pretty cool.
I ran DynDNS on my home computer, and this script would check if I was live online. If I was, it would show a button linked to my home machine webserver at mdw.penguinpowered.com – I ran slackware linux back then. Although my first CGI program was actually written in C back in 1994, this was a Perl script like absolutely everything I wrote for the web at that time.
There was no substantial change to this until I installed a WordPress blog in March 2006. Here’s a screenshot from June of that year showing my green on black design and some of the links and content.
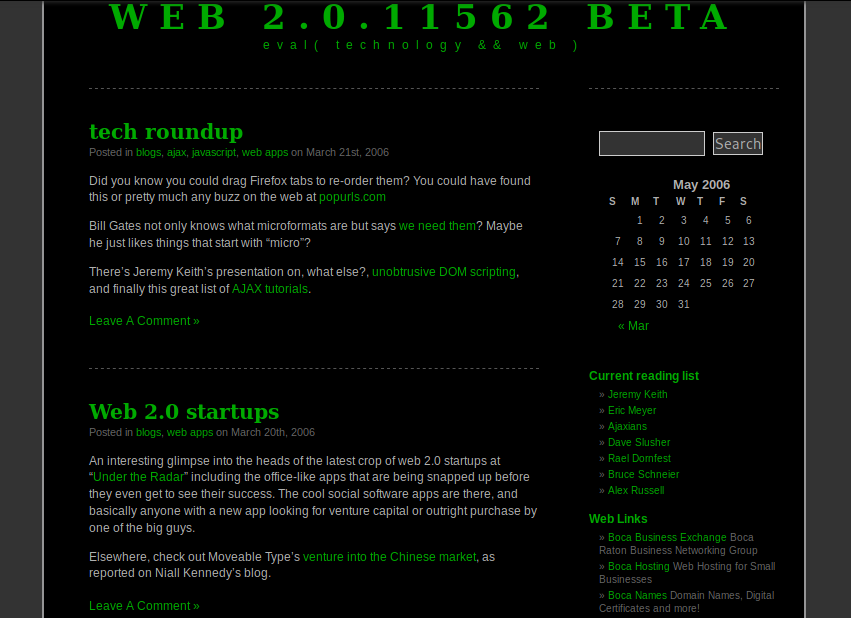
I was quite into building websites, as you’ll see if you peruse the posts and the links from back then. The next substantial change was recorded in January 2013, where I switched to a colorful theme and domain name based content. I had started a company called Boca Names LLC and was just starting a group called South Florida Domainers with another local domain investor, Stu Maloff. We had just held the first really successful domainers meetup the month before, and were all enthusiastic about it.
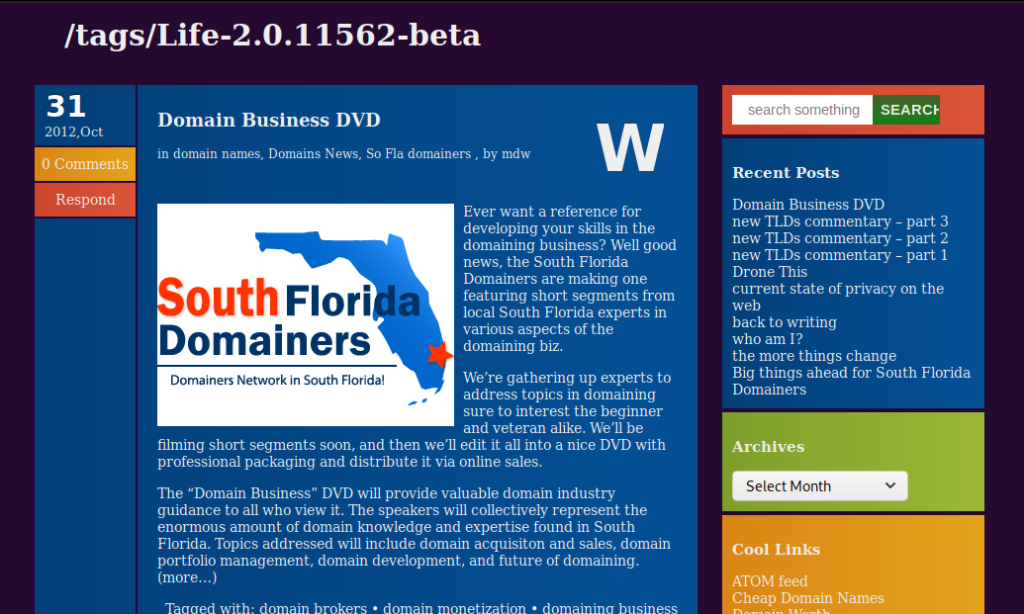
By late 2014 I was using a tasteful, minimalist theme and getting involved in blockchain projects. For the past year I had been writing articles and learning about how cryptocurrencies worked. Here’s the last screenshot in the series, once again thanks to the Wayback Machine at archive.org:
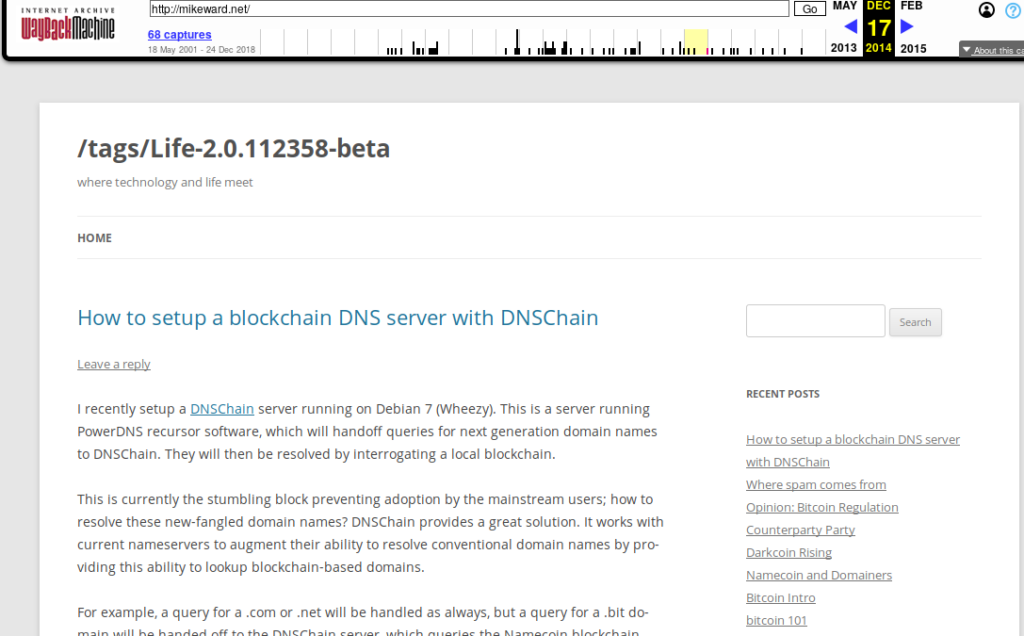
Well that’s it folks, the grand tour of mikeward.net archives brings us here – to a new start for this venerable domain. Let’s get started!