Multiverse 2.357
paused to apply patchesScrapy is a scrappy little web scraper you can use to scrape web content using CSS or XPath selectors and even Regex. Using CSS selectors is probably the easiest for people who are familiar with the web, but the hardcore user can even mix-n-match.
We can open a shell, a familiar technique to Python programmers, in order to test our scraping before unleashing it on the world.$ scrapy shell https://mikeward.net
This opens a shell and the HTTP request and response are now available to us, as you can see below.

As you can see, the request object is available, as is the response object. In fact I can get the request.method and request.url if I need to. I can search through the response object as shown, for the <title> tag, and extract this content using:>>> response.css('title').extract()
or just the text inside the title tags (the innerHTML):>>> response.css('title::text').extract()
The way to use this is to look at the target page using the inspector that’s built into your browser. Generally you can right click and choose “inspect” from the menu and see the structure of the HTML.
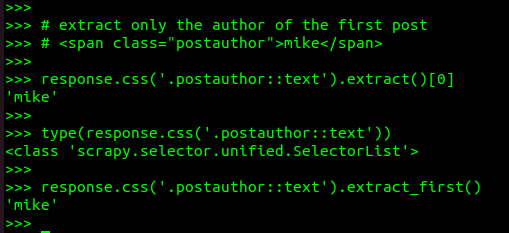
Above, we’re grabbing the first “author” shown on the page, from the first post. The author is displayed inside a SPAN tag with the postauthor class applied. Since there are a lot of these on the home page, we’ll get the first item in the list, or element zero.
To reach inside tags, we can use the attr() method, as shown above where we’re grabbing the content inside the HREF attribute. Below we use the CSS() method to get the content inside the HREF attribute of the first <A> element.

If the HTML is well-formed, meaning that it is nested correctly in a hierarchy, then we can use XPath to specify the content location. Starting from the root element, we describe a path down through the hierarchy to the target. The first example below shows how to specify the TITLE element, nested inside the HEAD element, inside the HTML parent element. In the second example, we specify all TITLE elements, and hope that there is only one as per the HTML specification.

One way to find the path to an element inside a page full of markup is to right click on a visible object in the page, and “copy xpath” onto your clipboard. Pasting that into an XPath query might look ugly, but should work:
>>> response.xpath('/html/body/div[1]/div[2]/span[2]').extract()['<span class="postauthor">mike</span>']
We could decide to simply get all of these, by eliminating the specific parts in this path, and extract the inner text only. Obviously I could use a few more writers.
>>> response.xpath('/html/body/div/div/span/text()').extract()['mike', 'mike', 'mike', 'mike', 'mike']
We might also notice that we only care about the SPAN tags with the class of postauthor, and decide to select authors like this:
>>> response.xpath('//span[@class="postauthor"]/text()').extract()
['mike', 'mike', 'mike', 'mike', 'mike']
To search for any <a> elements that are “python” tags in this blog, we might use the contains method with our xpath expression:
>>> response.xpath('//a[contains(text(), "python")]').extract()
['<a href="/category/python">python</a>', '<a href="/tag/python">python</a>']

Finally, we need to talk about using regular expressions in our queries. They can be used in CSS or XPath searches by using the re() method. So in the example above, we want all the <A> tags containing text strong beginning with the letter ‘P’ that are strings of length 5 or 6.
.re('P[a-z]{5,6}$')
Indicates that we want strings that start with ‘P’, followed by 5 or 6 lowercase letters and nothing else – indicated by the end of line marker $.
That last example using a regular expression was very specific. In general we don’t want to get more specific than we need to, because it makes our query brittle. That is to say that it will not work correctly as soon as something changes, so more general is often better.
There is a lot more to say about scrapy of course, and how to use it to scrape websites. We’re just beginning, and in the next post we’ll cover using spiders to crawl websites. This is a key part of using scrapy, so stay tuned!